Preface
This article was written in 2002 for the C/C++ User’s Journal. But when two years from submitting the proposal to still-not-published were gone, I put it on my first Website. This site is history, so I decided to re-publish it here.
Start
Having a flexible and dynamic way to log any data at any time asynchronously and in the correct chronological order is very helpful, especially in multi-threaded environments. For example, it provides a convenient way to trace application behaviour. But, as with multi-threading itself, one have to consider a few points to get things working as expected.
This article and its samples will show you one way to implement a dynamic, thread-safe, asynchronous, chronological logging mechanism in a multi-threaded environment, using the Observer and the Singleton design patterns, thread synchronisation via semaphores and critical sections, and a thread-safe queue based on std::queue. ‘Dynamic’ means you have the ability to start and stop logging at any time you like and have as many logging destinations as you want (and of course change them at runtime). The architecture of the logging mechanism shown in the article is helpful not only in multi-threaded environments, but also in single-threaded ones. I will start by showing the thread-neutral architecture of the logging mechanism, move on with a (single-threaded) class design, describe some of the problems you might run into when using this implementation in a multi-threaded application, and explain the changes required to make this thread-safe, asynchronous, and chronological correct. At the end I will present some parts of the resulting implementation in detail.The (Base) Architecture
Figure 1 shows the abstract, thread-neutral architecture of the logging mechanism. There are several objects, each of which needs to log some data. In the middle, there’s a distributor receiving these logging data packages and sending them to the corresponding logger, which in turn is responsible for generating the appropriate output. This basic architecture is the same for single- and multi-threaded applications.
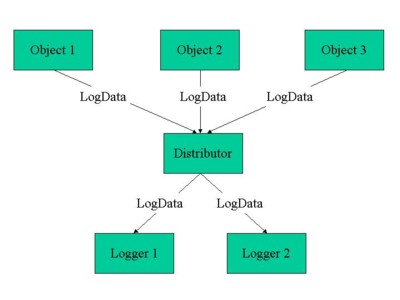
Figure 1: Abstract, thread-neutral logging mechanism architecture Of course, one might also leave away the distributor so the objects will send the log data directly to the desired logger. But what are the consequences? At least, each object would need to implement the clearinghouse logic encapsulated by the distributor. Depending on the implementation, this might include keeping a list of available loggers, some logic on logger calling rules, error handling if a logger is not available, and so forth. Technically, doing this is not such a big problem. But mixing up the responsibility of the objects (business logic and logging clearinghouse) will lead away from the ‘one class/function, one responsibility’ guideline and result in the loss of a centralized smart-clearinghouse service.
The Class Design
What follows is the description of the design for single threaded implementation. Although we will find that the basic architecture will not change a lot when switching to multiple threads, there will be some significant changes in the class design.
The disadvantages of leaving away the distributor, described above, give some hints about the design of several classes needed. As soon as the objects can’t decide which logger they will use to generate some logging output, the log data sent needs some more information than just the pure data. To be able to set something like a filter on the logger, a log message (that’s how I will call log data from now on) should consist of:– an area (for example system, user activity, database, file access; these can be combined),
– a level (for example exception, error, event, trace, debug; where error includes exception and so forth), and finally
– the logging data itself.
One might also add a timestamp or other decoration, but that’s not needed explicitly. The result is the class LogMessage. (Listing 1 shows a fragment of LogMessage.h.)
class LogMessage
{
public:
enum Area { evGUI=1, evCom=2, evUserActivity=4 };
enum Level { evError, evEvent, evTrace, evDebug };
LogMessage(const Area nArea, const Level nLevel,
LPCTSTR pszText);
...
private:
...
const std::string m_strText;
const Area m_nArea;
const Level m_nLevel;
};
Listing 1: Fragment of LogMessage.h
It should be clear that there must be only one distributor, otherwise the programmer does not have to decide which logger to use but now needs to choose the right distributor. That’s not what we’re aiming for. A natural way to implement a single distributor is as a Singleton, which is defined by Gamma et al. as a way to ‘ensure a class only has one instance, and provide a global point of access to it’ [1]. The distributor also must know all loggers currently available. This means it has to have a logger list, which can change at runtime. The distributor’s class name is LogDistributor. Gamma et al. describe the Observer Design Pattern as ‘… a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically’ [2]. As you can see in Figure 1, there is a one-to-many dependency between the distributor and the logger instances. The distributor changes state when a log message arrives (it now has a log message to be handed off for processing), and so some or all of the dependents (the loggers) need to be notified. The loggers can be called (log) observers from now on. The different kinds of log observers must be derived from a base class to make sure the distributor only needs one observer list to keep all the observers. Just as LogMessage has the information about the area and level the individual message belongs to, the observer needs to know about the area(s) and the level(s) it is to observe. It must be possible to define an observer that is responsible for multiple areas, so these messages might be logged to the same external resource. (Further, it would be good to avoid having several observers logging data into the same file, to avoid interleaved output and resource contention.) The name of the base class, which offers all these abilities, is LogObserver. (Listing 2 shows a fragment of LogObserver.h.)
class LogObserver
{
public:
enum Type { Console, Window, File };
LogObserver(const int iArea, const LogMessage::Level nLevel,
const Type nType);
virtual ~LogObserver() { }
virtual void Write(const LogMessage & rMessage) const = 0;
...
private:
...
const int m_iArea;
const LogMessage::Level m_nLevel;
const Type m_nType;
};
Listing 2: Fragment of LogObserver.h
Implementation Details
The code sample presented by Gamma et al. on the implementation of a Singleton does not satisfy me at all. In general, it leaves open the question of the destruction of the object when the application terminates. (One thing really important for the LogDistributor since it is responsible for the destruction of all LogObserver instances.) And since the LogDistributor is needed during the whole lifetime of the application, I’ve chosen an implementation simpler here. (Lots of people (including me, see [3] and [4]) had written a lot on the question of singleton destruction. Let me cite John Vlissides’ column ‘To Kill a Singleton’ (C++ Report, 1996) and Alexandrescu’s treatment of Singleton in his ‘Modern C++ Design’ book here.)
The implementation I chose for LogDistributor’s single instance is quite simple (please note that this design decision is not appropriate for all real-world Singletons):
/* static */
LogDistributor & LogDistributor::Instance()
{
static LogDistributor instance;
return instance;
}
The second detail I will point out is the way a log message is handled by the LogDistributor. Instead of just looping through the log observer list and passing the message to the output method of each observer, the distributor first checks if the observer’s and message’s area and level match. This is not very important in single-threaded applications, but since I want to reduce the runtime impact of the logging mechanism as much as possible, this behaviour is very important, especially in multi-threaded environments, as we will see later.
Interlude
The architecture and class design presented above is all you need to implement dynamic logging in a single-threaded application. Any class that wants to log something is able to do so without knowing if there is an observer active or not. The class’ implementer does not have to care about it. That’s the job of the LogDistributor. When implementing a logging activity, you also don’t have to care about the output destination (console, file, SMS, e-mail, …). The application’s user has the freedom to choose the output destination of any kind of message from the list of available log observer types. (Of course, someone has to implement all the different types of observers.) There are only two things you have to define at the moment when you implement the logging: the area to which the message belongs and the message’s log level.
The DynamicObserver project inside the sample solution demonstrates how to implement the classes presented above, how to add and remove log observers during runtime, and how to define a user interface for the administration of log observers.
Multiple Thread Considerations
Now it’s time to leave the ‘bright’ world of step-by-step command processing and enter the ‘dark’ world of multiple threads.
Ah, no, multiple threads aren’t that bad. They just make it a little bit harder to imagine the sequence in which commands are processed; often it is impossible to imagine all possibilities. And that’s not the only challenge. On single-processor boxes, the execution of one command of one thread might be interrupted by the execution of another command of another thread. On multi-processor machines, however, different threads really run at the same time. As long as different threads do not try to access the same data or resources at the same time, there’s no problem. Unfortunately, in the logging architecture this is exactly what will happen: The log classes have to be responsible for making sure that all log messages are written to the output device in the order of logging. Also, there must be a guarantee that the log messages are not mixed up on the output device; for example, one message must be completely output before the next one begins. Of course no log message must be dropped or ‘forgotten’ by the distributor or the observer. And still there should be the ability to start and stop observers at any time. Sounds like lots of work, but fortunately, it turns out that it is not too hard.Decoupling Distribution and Output Creation
When we look back to the single-threaded world, the LogDistributor calls each LogObserver (with the matching log level and area) to handle the message, and the program execution breaks until the message is completely output. This is one option for multithreaded applications too, but doing it this way would prevent multiple logging threads from running concurrently. (After all, output to different log devices can usually be done in parallel without resource contention, and so it would be natural to want loggers to run on multiple threads so as to get a few tasks done in parallel, instead of sequentially,)
What needs to be done is to decouple the log message distribution from the output creation. My approach does this with two changes to the single-threaded architecture and design. The first thing is to make each LogObserver run inside of its own thread. Doing so gives the main application the ability to continue working while the LogObserver is creating the message output. But just having the LogObserver running in a separate thread won’t help by itself, because each time the LogDistributor wants to pass a new message to the observer while it is already in the process of creating a message output, the calling thread would be blocked again. To solve this problem, I have added message queuing to the architecture. There is not just a single queue, but one queue for each observer. And as a reminder for implementation, this queue needs to be thread safe since different threads will access it: the thread executing the LogDistributor to add new messages, and the log observer thread to process and remove them.The Multiple Thread Architecture and Execution Order
Have a look at Figure 2, which shows the multi-threaded architecture and execution order. As described above, the architecture itself only changed slightly from the original version in Figure 1. Just two queues were added, holding the log messages for the two observers. So now there are four players in the game instead of three shown in Figure 1: The objects doing the logging, the LogDistributor, the LogObserver, and the newly added LogMessageQueue.
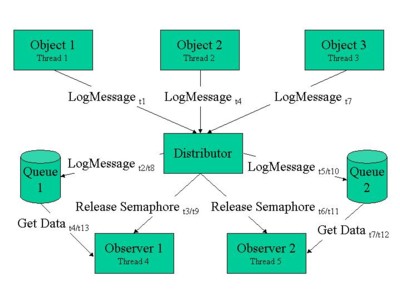
Figure 2: Multi-threaded architecture and execution order
Now consider one part of Figure 2’s execution order in detail. Object 1 passes a LogMessage to the distributor (t1). To guarantee the right logging sequence, the LogDistributor must enter a critical section (or similar facility to serialize access to shared data) when passing the message to the observer, which is done indirectly via the message queue. During this time, no other thread is able to log. (In other words, another thread trying to log is blocked until the former message is distributed.) LogDistributor first adds the message to the corresponding queue (at time t2), and then releases a semaphore (t3) to wake up observer 1 with a notification that there’s a new message to process1. At t4, both observer 1 is able to retrieve the message from the queue and object 2 is able to pass a new LogMessage to LogDistributor. Again: This might happen at the very same time since both are running inside their own threads. But now, that’s no problem any more. Observer 1 can take all the time it needs to create the logging output. (Perhaps it’s an observer that generates an e-mail and sends it via the Internet, which is very time consuming [create the mail, connect to the Internet, …].) But it does not block the other threads. Even if there are messages added to its queue while it is processing one (t8): The semaphore is released for each (t9), the queue won’t lose a single one, and so the observer will not miss any.
The rest is straightforward: The message passed to the distributor at t4 is added to queue 2 (t5), observer 2’s semaphore is released (t6), and while object 3 is passing its logging information to the distributor, observer 2 is processing the new message (t7). The latest log message (sent by object 3) is added to queue 1 (t8) and queue 2 (t10). But since observer 2 just has to print some data to the console, it is much faster than observer 1 and processes this messages much earlier (t12) than observer 1 will (t13). And because each observer has its own message queue, that’s not problem either. Both observers will process the last message.Changes in LogDistributor
Next, note the changes needed to make LogDistributor multi-thread-ready. The main change to LogDistributor was already mentioned by the description of the execution order above: The LogDistributor needs a critical section (or something similar) to serialize access each piece of shared data, here the queue of each registered log observers. The LogDistributor holds a critical section object as a member to save expensive initalization / destruction time of the system resource. It is initialized once in LogDistributor’s constructor and deleted in its destructor. Having the single instance of LogDistributor defined as a static local variable makes sure its destructor will be called, and so the system resource ‘critical section’ will be released.
The critical section is used at three places. When an observer is added, when a log messages is passed to the registered observers, and when an observer is removed — or, in short: every time there’s a need to access the shared data, to iterate over the list of registered observers2. This is essential since the list must not change during iteration. Otherwise it might happen for example that while one thread logs some data, another is destroying the observer in the moment before the LogDistributor calls it, while the distributor assumes it still has a valid pointer to the object that’s just disappeared. The result? An immediate crash if you’re lucky, some obscure behaviour if not. Of course you have to use the same critical section every time you want to touch the shared data, to ensure that all access to the shared data will be correctly serialized. As long as it is locked by one thread, any other thread trying to become owner is blocked. Blocking other threads doesn’t sound very good, and I’m afraid at least there is no way out. But: Only these threads are blocked, which are trying to log a message while the LogDistributor is in the process of distributing another message. And the runtime impact is reduced as much as possible: By only passing the log message to those observers that are observing the area and level of the message, and by decoupling the message distribution from the output creation by using a message queue. (Please see annotation below.)The LogMessageQueue
As already said, also the LogMessageQueue must be thread safe. That’s because it is possible that LogDistributor tries to add a LogMessage while LogObserver just retrieves one. Again, I’m using a critical section here, analogous to the one of LogDistributor, which is a member of the LogMessageQueue class. I’ve implemented this class as a has-a std::queue instead of is-a (for more on this, please see Herb Sutter’s Exceptional C++ [5]). This is done to make sure the only way to access the messages is to use the synchronized methods.
Conclusion
As soon as you consider the special requirements of multi-threaded applications and use the abilities of thread synchronisation, even asynchronous logging with chronological correctness in a multi-threaded environment is no magic. The most important point here is to have a solid architecture and design, which take into consideration the additional possible behaviours of multi-thread applications and take care of synchronized data access. Looking at the code of the multiple-thread sample
(AsyncDynamicObserver project in the sample solution), you will notice that the implementation still is very simple. There are only a few lines of code on each class (LogObserver, LogMessageQueue, LogDistributor, the main actors).
Acknowledgements
I’d like to thank Eberhardt Immhof, who gave me the initial idea on the thread-neutral architecture. Thanks also to Rainer Sinsch for his tip on how to implement console output in windows applications, to Alfred Laux for his input on implementation details of the sample applications, and to both of them for their patience and feedback when introducing the multiple thread design and implementation. Of course I have to thank Herb Sutter for his invaluable comments and suggestions, especially on the non-exclusive lock.
[1] Design Patterns, Elements of Reusable Object-Oriented Software, Erich Gamma et al, Addison-Wesley, 1995, p. 127
[2] Ibid, p. 293
[3] Let’s Talk About… Singleton, The Electronic Developer Magazine for OS/2 (www.edm2.com), Volume 5, Issue 12, Stefan Ruck, 1997
[4] Singleton – The Next Generation, The Electronic Developer Magazine for OS/2 (www.edm2.com), Volume 7, Issue 5, Stefan Ruck, 1999
[5] Exceptional C++, 47 Engineering Puzzles, Programming Problems, and Solutions, Herb Sutter, Addison-Wesley, 2000, p. 88ff
|
Footnote 1 If LogDistributor first releases the semaphore and then adds the message to the queue, there is the risk that observer 1 tries to retrieve the message from the queue before the distributor was able to add it into. Remember: Each observer is running inside of its own thread, so it might be ‘faster’ than the distributor. That’s multi-threading!  |
|
Footnote 2 The LogDistributor’s critical section is only needed to serialize the access to the list of registered observers. Each LogMessageQueue holds its own critical section to serialize the access to it.
|
|
Annotation Thread Blocking Decoupling the logging from the distribution may reduce even this blocking time. Accordingly to the decoupling of distribution and output creation, an additional message queue must be introduced. This message queue belongs to the LogDistributor and keeps all messages to log. Also, the LogDistributor must do the distribution asynchronously from the logging, so it has to run in its own thread. Now any time a thread is going to log, the new message is just added to the LogDistributor’s message queue. Corresponding to the distribution, every time a message is added to the queue, a semaphore is released to tell the LogDistributor there is some work to do. In the LogDistributor’s thread, now independent from the thread that generated the message, the distribution is done asynchronously, but still chronologically correct. While the new message becomes distributed, there is already the chance for another thread to add a new message to the distribution queue. So the potential blocking time is reduced to the time needed to add a message to the distribution queue. The time needed to distribute the message to all observers has no influence any more on the thread that is creating a log messages. In my personal view, the time needed to distribute the messages is neglect able, so there’s no need to decouple the logging from the distribution. But I do not know all requirements of all the world’s applications, so I do not want to conceal these additions from you. The sample code on this can be found in the DistributorMQ project of the sample solution. Another approach is to use a non-exclusive lock on the observer list for read-only access and an exclusive lock when the list should be changed. This exclusive lock will block any thread trying to log until the list has changed. Depending on the application, there might be an advantage. As long as there are only a few or no changes to the observer list during runtime, the blocking time is minimized. If there are a lot changes to the list, the logging threads are blocked very often. Also, the implementation is not trivial. One has to implement a ‘pending-exclusive-lock’ state and a list of pending exclusive locking threads to guarantee fairness and non-starvation. As soon as there is an exclusive lock pending, no other thread should be able to log any more until the exclusive lock was processed. But at least even with this approach there is still a potential thread blocking given. To me, the implementation of it is too heavy weighted, regarding the time a thread blocking may take. |
|
Sample Code The sample code contains one VS 2012 solution with three projects: DynamicObserver demonstrates how to implement the single-thread model presented above, how to add and remove log observers during runtime, and how to define a user interface for the administration of log observers. AsyncDynamicObserver extends the sample code by the multiple-thread implementation described in this article. DistributorMQ decouples even the logging from the distribution to reduce blocking time as much as possible. All code samples are Windows MFC applications, originally developed under MS Visual C++ 6.0. The code was only modified to compile an run under VS 2012. No newer C++ features were added. The VC++ 6.0 project files are included too. In case you start one of the demo apps, and no console windows can be seen: just reduce the size of the main window. It might hide the console window that is opened when the application starts. You need the console window to see the output of the console observer. |